
Operational RAG Done Right: The Data Backbone for AI-Powered Business Process Automation
Introduction: Why Operational RAG is the backbone for trustworthy, action-taking AI
Generative AI is racing from experiments to execution—and the stakes are high. According to the McKinsey State of AI 2024, 87% of organizations expect GenAI to be highly disruptive in the next three years, 65% are piloting or adopting it, yet only 6% have risk controls fully in place. That gap is exactly where projects stall or backfire—and exactly where a governed, operational RAG backbone earns its keep by making AI reliable, auditable, and ready for production at enterprise scale. See McKinsey State of AI 2024.
Operational RAG (Retrieval-Augmented Generation) is not just about getting the right answer—it’s about taking the right action and proving why. In Microsoft-centric businesses, that means grounding AI in Dataverse/Fabric semantics, enforcing policies with DLP, tracking lineage in Purview, and orchestrating actions across Power Platform with full auditability.
This post is an actionable blueprint for Power Platform and AI agent developers—and SMB leaders—who want automation that ships fast, stays governed, and scales without vendor lock-in. We’ll cover hybrid retrieval (vector + relational), a governed semantic layer, change data capture for freshness, and end-to-end lineage and policy enforcement. We’ll close with a 4-week pilot plan and how B. Cobra Systems accelerates delivery while keeping your options open.
What makes operational RAG different from Q&A RAG (and why it matters for automation)
Q&A RAG focuses on answering questions. Operational RAG is built to trigger actions with confidence.
Key differences:
– Objective: Q&A returns a response; operational RAG performs an action (create a case, route an order, update a record), along with the why and the how.
– Constraints: Operational RAG respects business rules, policies, approval paths, and audit requirements; Q&A RAG typically does not.
– Data fidelity: Operational RAG needs transactional freshness and semantic consistency (entities, KPIs, policies) to avoid bad actions.
– Traceability: Decisions must be explainable end-to-end with lineage, sensitivity labels, and user-level access controls.
– Evaluation: Beyond answer correctness, you must measure action success, safety, drift, and impact on KPIs.
The bar is higher because consequences are real: inventory moves, customer promises change, money flows. Operational RAG requires a governed data backbone and action orchestration that Q&A experiments rarely include. Microsoft’s RAG guidance emphasizes hybrid retrieval, grounding in authoritative sources, and rigorous evaluation—tenets that become non-negotiable when agents take actions. See Azure AI RAG best practices.
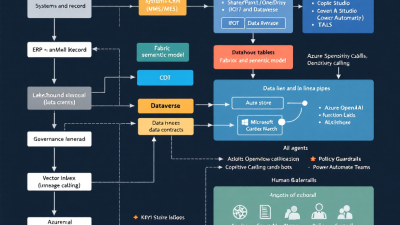
Reference architecture at a glance: Power Platform + Fabric + Azure OpenAI + Purview
Anchor platforms:
– Power Platform: Dataverse, Power Automate, Power Apps, Copilot Studio for agents, ALM pipelines, DLP policies.
– Microsoft Fabric: OneLake, Eventstream, Pipelines, Lakehouse/Warehouse, Semantic Models, and lineage.
– Azure OpenAI + Azure AI Search: LLM orchestration with retrieval, semantic ranker, and enterprise security.
– Microsoft Purview: Catalog, lineage, sensitivity labels, and governance across services.
Flow of data and decisions:
1) Source systems (ERP/CRM/WMS/MES/SaaS) feed Dataverse and/or Fabric via CDC.
2) Fabric stores raw and curated data in OneLake; Semantic Models define governed entities and KPIs with RLS/OLS.
3) Retrieval index (Azure AI Search) ingests curated content, document chunks, and structured metadata; hybrid retrieval combines dense vectors + lexical keywords + filters.
4) LLM calls are grounded on retrieved evidence and the semantic layer; policies and safety filters are applied.
5) Actions are executed through function calling/tool catalogs in Copilot Studio and orchestrated by Power Automate/Dataverse plugins with approvals and audit trails.
6) Purview and Fabric lineage track data and decision flow end-to-end; DLP enforces connector boundaries.
7) Telemetry, evaluation, and drift detection close the loop.
Relevant platform capabilities:
– Hybrid retrieval and semantic ranking: Azure AI Search
– Operational freshness: Dataverse change tracking and Synapse Link, plus Fabric Eventstream CDC: Dataverse change tracking, Synapse Link for Dataverse, and Fabric Eventstream CDC
– Governance and lineage: Microsoft Purview lineage and Fabric lineage
– Semantic layer: Fabric Semantic Models
– Safety and policy enforcement: Azure AI Content Safety, Power Platform DLP, and Power Platform ALM
– “On your data” retrieval with enterprise security: Azure OpenAI on your data
Data sources and contracts: ERP/CRM/WMS/MES, Dataverse, APIs, and agreed schemas
Operational RAG is only as good as its contracts with source systems. Define:
– System of record: For each entity (Order, Customer, Inventory, Case), specify authoritative source(s) and write-back rules.
– Freshness SLAs: Which attributes need second-level freshness (e.g., inventory availability) versus hourly/daily (e.g., pricing tiers)?
– Access model: RLS/ABAC requirements, sensitivity labels, PII/PCI/PHI boundaries, and service identities.
– Schemas and semantics: Normalize across disparate systems into business entities in Dataverse/Fabric; codify relationships and policies.
– API contracts: Rate limits, error handling, idempotency, retry/backoff, and partial failures.
Dataverse provides change tracking for incremental reads, enabling near real-time sync to analytics and search indexes via Synapse Link; this is foundational for keeping the RAG context fresh. See Dataverse change tracking and Synapse Link for Dataverse. Fabric’s Eventstream CDC captures changes from streaming and database sources with low latency, feeding OneLake and downstream indexes with lineage. See Fabric Eventstream CDC.
Tip: Treat your RAG corpus as a product. Publish a contract: update cadence, field dictionary, provenance tags, sensitivity classification, and downstream consumers.
Hybrid retrieval patterns: vector + relational + keyword for precision and recall
One-size retrieval does not fit all. Operational agents need both precision (don’t act on the wrong policy) and recall (don’t miss the exception clause buried in a PDF).
Recommended pattern:
– Vector search for semantic similarity using embeddings over curated chunks (policies, SOPs, product specs).
– Keyword/sparse (BM25) search to align on exact terms, part numbers, and regulatory phrases.
– Relational filters to enforce business constraints: region, customer segment, SKU, effective dates, approval tier.
– Reranking with a semantic ranker for final ordering.
Azure AI Search natively supports hybrid retrieval with dense vectors plus sparse lexical signals, enhanced by a semantic ranker to improve relevance for RAG. See hybrid retrieval in Azure AI Search.
Design choices that matter:
– Chunking: Aim for self-contained, policy-aware chunks (e.g., 300–800 tokens) with overlap tuned by evaluation. See RAG best practices.
– Metadata-first filters: Pre-filter by entity, effective date, region, and version before vector search to reduce noise and cost.
– Fielded search: Index references like order IDs, SKUs, and customer IDs for deterministic joins to Dataverse/Fabric entities.
– Freshness caches: Maintain a small “hot” index for fast-moving facts (inventory, outages) and a larger “cold” corpus for reference docs.
Designing the semantic layer: business entities, policies, and Dataverse/Fabric models
The semantic layer is where “data” becomes “the business.” Use Dataverse for operational entities and Fabric’s Semantic Models (Power BI datasets) for governed analytics, KPIs, and security models. Fabric provides role-based and object-level security, XMLA-based lifecycle management, and shared semantics across tools. See Fabric Semantic Models.
Principles:
– Canonical entities: Define Orders, Customers, Inventory, Cases, Incidents, Work Orders with shared keys and lineage back to sources.
– Policy-as-data: Represent policies, approval thresholds, and exception rules as versioned tables with effective dating—not hard-coded into prompts.
– Security in the model: Implement RLS/OLS to ensure agents and users only retrieve and act on what they’re allowed to see.
– Metric truth: Publish KPI definitions (e.g., On-Time Ship, Fill Rate, CSAT) so prompts and agents reference consistent metrics.
– Explainability fields: Store provenance, version, and policy references alongside actions for audit exports.
This semantic backbone keeps prompts small and unambiguous; the agent asks the model, not the world.
Freshness with change data capture: Event Streams, ADF/Fabric pipelines, and sync SLAs
Operational agents decay quickly with stale context. Build a freshness pipeline:
– Change capture from systems of record:
– Dataverse change tracking plus Synapse Link to land incremental deltas in OneLake. See Dataverse change tracking and Synapse Link.
– Fabric Eventstream CDC for databases, IoT, and streaming sources with low-latency ingestion. See Fabric Eventstream CDC.
– Transformation and enrichment: Use Fabric pipelines/dataflows to curate entities and publish to Semantic Models with lineage.
– Index sync: Trigger partial reindex on affected chunks/documents in Azure AI Search; maintain a fast lane for critical attributes (inventory) and a batch lane for docs.
– SLA tiers: Define gold (sub-minute), silver (15–30 min), bronze (daily) freshness by entity/attribute.
Fabric and Power BI provide end-to-end lineage across workspaces, datasets, dataflows, and reports, enabling traceability from operational sources to agent decisions. See Fabric lineage.
Lineage, security, and governance: Purview, sensitivity labels, RLS/ABAC, and audit trails
Governance is how you move from demo to durable operations.
– Catalog and lineage: Register sources, OneLake tables, Semantic Models, and search indexes in Purview for discovery and automated lineage across Power BI, Fabric, and Azure data services. See Microsoft Purview lineage.
– Sensitivity labels: Apply labels to columns and datasets; propagate labels to downstream artifacts and mask PII where required.
– Access control: Enforce RLS/OLS in Semantic Models; use ABAC where applicable for attribute-based decisions (e.g., region).
– DLP policies: Classify connectors as Business, Non-Business, or Blocked and enforce at tenant/environment/solution levels to keep agents from exfiltrating data. See Power Platform DLP.
– Safety filters: Integrate Azure AI Content Safety for text filtering, severity scoring, blocklists, and prompt shields, especially for user-generated inputs. See Azure AI Content Safety.
– CoE oversight: Use the Power Platform CoE Starter Kit to monitor environments, inventory makers/solutions, and standardize deployment practices. See CoE Starter Kit.
All actions should be solution-aware with ALM pipelines and audit logs in Power Automate/Dataverse, making it easy to trace who/what/when/why for every step. See Power Platform ALM.
From retrieval to action: function calling, tool catalogs, and Power Automate orchestration
The handoff from “knowledge” to “change something” is where reliability is won.
– Tool catalog: Define allowed actions (e.g., create case, update order hold, schedule technician) with input schemas, validation rules, and preconditions.
– Function calling: Use structured tool invocation from the LLM to call Dataverse actions, Power Automate flows, or custom APIs. Validate inputs against schemas before execution.
– Orchestration: Implement multi-step flows with rollback points, compensating actions, and human-in-the-loop approvals for higher-risk operations (credits, policy overrides).
– Permissions: Run as a service principal with least privilege; map tools to roles and apply RLS/ABAC checks at execution time.
– Evidence bundle: Attach retrieved citations, policy versions, and semantic model snapshots to each action record for auditability.
Reliability patterns: grounding, constrained outputs, approvals, and rollback playbooks
Build for correctness by design:
– Grounding: Force responses to cite the semantic layer or indexed documents; reject or escalate if evidence confidence is low. See RAG best practices.
– Constrained outputs: Use JSON schemas, enumerations, and regex validators; never free-form critical fields (amounts, SKUs, IDs).
– Guardrails: Apply Azure AI Content Safety classification and blocklists; route high-risk content to human review. See Azure AI Content Safety.
– Approval matrices: Encode dollar thresholds, customer tiers, and exception criteria in Dataverse tables; Power Automate routes for approval with audit trails.
– Rollback playbooks: For each action type, define compensating steps (e.g., revert inventory, re-open case), safe time windows, and automated triggers.
Evaluation and telemetry: gold sets, A/B tests, drift detection, and success KPIs
Operational RAG must be continuously measured.
– Gold sets: Curate representative scenarios with expected outcomes and acceptable ranges (e.g., correct escalation path, right SLA).
– Offline evaluation: Evaluate retrieval precision/recall, grounding coverage, and answer correctness using Azure AI Studio’s evaluation features. See Azure AI Studio evaluation.
– Online A/B: Compare prompts, retrieval configs, and tool strategies; measure completion rates, approval latency, and error rates.
– Drift detection: Monitor changes in embeddings distribution, retrieval quality, and policy usage; alert when performance deviates.
– Success KPIs:
– Operational: First-contact resolution, order exception cycle time, mean time to schedule, approval lead time.
– Quality: Grounding rate (% actions with citations), override rate, rollback rate.
– Safety/Governance: DLP violations prevented, PII exposure incidents, audit completeness.
– Cost/Performance: Cost per successful action, latency p95.
Cost and performance tuning: chunking, hybrid filters, caching, and embedding strategy
Keep it fast, relevant, and affordable:
– Chunking and overlap: Right-size chunks (e.g., 400–600 tokens) to reduce token costs and improve retrieval evaluation; optimize with AB tests. See RAG best practices.
– Hybrid filters first: Use metadata filters to narrow candidate sets before dense similarity search; cheaper and more precise.
– Caching:
– Retrieval cache: Cache top-k results per query signature with short TTLs.
– Response cache: Cache deterministic grounded responses for FAQs with invalidation on CDC events.
– Embeddings strategy: Use a single primary embedding model for consistency; store versioned embeddings; re-embed only affected chunks on policy updates.
– Index tiers: Maintain a hot index for volatile facts and a cold index for reference content; route queries accordingly.
– Prompt budgeting: Enforce max context windows; summarize chains of evidence with citations rather than flooding the prompt.
SMB starter playbook: a 4-week pilot on Power Platform with minimal net-new infra
Week 0 (preflight)
– Choose one high-value, low-risk scenario (e.g., order hold resolution, RMA guidance).
– Confirm data access and connector approvals; define SLAs and success KPIs.
Week 1: Data and retrieval backbone
– Enable Dataverse change tracking/Synapse Link; ingest needed tables into Fabric OneLake. See Dataverse change tracking.
– Stand up a minimal Semantic Model for key entities and KPIs. See Semantic Models.
– Create an Azure AI Search index; load curated docs and semantic metadata; configure hybrid retrieval and semantic ranker. See Hybrid Search.
Week 2: Agent and orchestration
– Build a Copilot in Copilot Studio with function calling against a small tool catalog (create case, update status).
– Orchestrate actions with Power Automate flows; add approvals for risky operations. See ALM.
– Apply DLP policies and Content Safety for inputs. See DLP, Content Safety.
Week 3: Evaluation and guardrails
– Create gold sets; run offline evaluation in Azure AI Studio; tune chunking, filters, and prompts. See Evaluation.
– Instrument telemetry: success rate, grounding rate, approval latency; configure alerting for drift.
Week 4: Governance and go-live
– Register assets in Purview; verify lineage and sensitivity labels. See Purview lineage.
– Implement ALM pipelines and CoE governance dashboards. See CoE Starter Kit.
– Launch to a pilot group; run A/B tests and weekly ops reviews.
Outcome targets:
– ≥20% reduction in handling time for the chosen scenario.
– ≥90% grounding rate; ≤2% rollback rate.
– Documented lineage and audit trail for all actions.
Case mini-scenarios: customer service deflection, order exception handling, field ops
Customer service deflection
– Trigger: Customer asks for warranty coverage.
– Retrieval: Hybrid search pulls product’s warranty PDF, policy version, and purchase record.
– Action: Copilot generates a compliant response with coverage terms; offers to initiate RMA via approved tool call if eligible.
– Guardrails: Content Safety on user input; approval required for goodwill exceptions.
Order exception handling
– Trigger: Order flagged due to credit risk.
– Retrieval: Semantic model provides customer segment, AR status; index yields policy thresholds.
– Action: Agent proposes options—place on hold, partial release, or request override—then executes post-approval with rollback defined.
– KPI impact: Reduced cycle time and fewer revenue-impacting errors.
Field operations scheduling
– Trigger: Machine telemetry signals a fault; Eventstream CDC updates device status.
– Retrieval: Index provides SOP and parts availability; semantic layer confirms technician skills and SLA.
– Action: Agent schedules the nearest qualified tech, reserves parts, and creates a work order in Dataverse.
– Safety: If confidence < threshold or SOP conflict detected, escalate to dispatcher.
Build, buy, or blend: avoiding lock-in while leveraging Copilot Studio and open stacks
You can go far on Microsoft-native services, but you shouldn’t paint yourself into a corner.
- Buy (native) where governance and speed matter: Copilot Studio for copilots; Power Automate for orchestration; Dataverse/Fabric for data and semantics; Azure AI Search for hybrid retrieval; Azure OpenAI for “on your data” security. See Copilot Studio and OpenAI on your data.
– Blend with open components where it helps: Keep your chunking, indexing, and evaluation pipelines portable; maintain embedding vectors in open formats; abstract vector stores behind an interface to swap in Postgres/pgvector/FAISS if needed.
– Standardize on contracts: Use Dataverse table schemas and Fabric Semantic Models as the stable backbone; they outlive model swaps.
– Platform engineering mindset: Reusable connectors, governance, and paved roads reduce time-to-value—developers spend 60–70% of time on maintenance and integration, so platform leverage pays off. See Gartner on platform engineering.
Net: Build on the Microsoft backbone for governance and speed, but design your retrieval and evaluation tiers to be model- and store-agnostic.
Implementation checklist and migration patterns for scaling safely
Minimum viable guardrails
– DLP policies configured; connectors classified
– Content Safety enabled on user inputs and model outputs
– RLS/OLS in Semantic Models; service principals with least privilege
– ALM pipelines for solution-aware deployments; audit logs verified
Data and retrieval
– Dataverse change tracking and Synapse Link active
– Fabric Eventstream CDC or pipelines for non-Dataverse sources
– Hybrid index in Azure AI Search with metadata filters and semantic ranker
– Chunking and embedding strategy versioned; re-embed playbook documented
Agent and orchestration
– Tool catalog with JSON schemas and validation
– Function-calling with input/output constraints
– Approvals and rollback playbooks aligned to risk tiers
Evaluation and operations
– Gold sets and offline evaluation baselined
– Online A/B configured; telemetry dashboards live
– Drift detection thresholds and incident runbooks
Migration patterns
– Start with “read-then-ask” (advisory actions) → progress to “ask-then-act” with approvals → “act-then-notify” for low-risk, high-confidence tasks.
– Expand retrieval domain by domain (customer service → order management → field ops), each with dedicated gold sets.
– Evolve embeddings and indexes behind stable semantic contracts; don’t change your data backbone every time you tune retrieval.
How B. Cobra Systems helps: architecture, governance, and delivery accelerators + CTA
B. Cobra Systems, LLC specializes in operational RAG and AI-powered automation on the Microsoft Power Platform. We bring:
– Blueprinted architectures: Reference implementations for Power Platform + Fabric + Azure AI Search + Azure OpenAI with Purview lineage and DLP baked in.
– Governed semantic layers: Fast-track Dataverse/Fabric Semantic Models with RLS/OLS, policy-as-data, and versioning.
– Retrieval accelerators: Production-ready pipelines for hybrid indexing, chunking templates, evaluation harnesses, and drift monitors aligned to RAG best practices.
– Orchestration patterns: Tool catalogs, function-calling scaffolds, approval matrices, and rollback playbooks running on Power Automate and Copilot Studio. See Copilot Studio.
– Governance-at-day-one: Purview registration and lineage, DLP policies, CoE Starter Kit rollout, and ALM pipelines so pilots are production-ready. See CoE Starter Kit and ALM.
– No lock-in delivery: We prioritize open schemas, portable embeddings, and interface-abstracted retrieval so you can mix Microsoft-native services with open alternatives as your needs evolve.
If you’re ready to ship AI agents that act with confidence—and prove it—let’s build your first operational RAG pilot in four weeks. Contact B. Cobra Systems to get a tailored blueprint, hands-on implementation, and a runway from pilot to production that stays fast, governed, and vendor-flexible.
Citations
– Industry urgency and risk controls: McKinsey State of AI 2024
– Hybrid retrieval and semantic ranking: Azure AI Search
– Dataverse CDC and Synapse Link: Change tracking, Synapse Link
– Fabric Eventstream CDC and lineage: Eventstream CDC, Fabric lineage
– Purview governance and lineage: Microsoft Purview
– DLP policies: Power Platform DLP
– Content Safety guardrails: Azure AI Content Safety
– CoE Starter Kit governance: CoE Starter Kit
– Copilot Studio for enterprise copilots: Copilot Studio
– RAG best practices and evaluation: RAG best practices, Evaluation
– Fabric Semantic Models: Semantic Models
– OpenAI on your data: Azure OpenAI on your data
– ALM and auditability: Power Platform ALM
– Platform engineering and time-to-value: Gartner